



Why and How to Clean Agronomic Data


Plenty of challenges come with managing growers’ data. Defining when one crop year ends and the next begins. Establishing boundaries. And trying to work with inconsistent, inaccurate, or ‘dirty’ data tops the list.
Editor’s note: This is the first part of a two-part series on data clean-up and proper management. This article shares tips to “rescue” or clean up bad/dirty data. The second part will explain how to properly set up beforehand so there won’t be a need to go back and clean it.
There is a lot of talk about rescue treatments when a crop is in danger of severe loss due to an under-application of a herbicide, a lack of fertility, or to fight off an impending infestation. That same conversation can be applicable when it comes to agronomic data.
Plenty of challenges come with managing growers’ data. Defining when one crop year ends and the next begins. Establishing boundaries. And trying to work with inconsistent, inaccurate, or ‘dirty’ data tops the list.
While dirty data often refers to mistakes made when manually entering it into a spreadsheet or other software, the concept can also be applied to data that’s simply not set up correctly, recorded correctly, or done with consistency. The whole point of collecting data is to use it to make better agronomic decisions. If that data isn’t accurate or seems questionable, it can’t be used confidently or to its fullest potential.
MORE BY JACOB MAURER





But there is hope for this data.
Rescue Treatments
The good news is, cleaning up – or applying a “rescue treatment” to – dirty data may be an option in some situations. The bad – or maybe I should say, challenging – news is, there are a couple things to keep in mind with any rescue treatment.
First, they do not always work. There are often times when the data’s quality just does not meet the standard necessary to be confident. Especially when dealing with items like test plots or field trials, the accuracy of a guidance system’s point data and the ability to line up base layers can be critical. If you are unable to overlay one dataset over the other, the digital copy of the trial for analytics or decision making can seemingly have no value.
Second, they do not always apply to everything. Unfortunately there is no “cure-all” when it comes to dealing with farm data. There are times when the problem is hardware related. Every now and then the problem lies with the software or in file corruption. Other times, the problem lies solely with the operator. In those cases, it takes a change in the actual method or practice by which the data is collected.
Knowledge Base
The important role as a farm’s data manager requires getting to know more than just the lay of the grower’s land and being able to re-create it in the computer. It also takes getting to know his or her fleet.
The ability to recognize the format a grower’s files are coming from and understanding what your own software needs to process them will further enhance your value to them, especially when it comes to exporting prescription files.
If a grower has a John Deere in the fleet, getting to know the GreenStar file format process will be important. Case IH end-users will want to understand Voyager files. Precision Planting cooperators will work almost exclusively with .dat files with the 20/20 Seed Sense but will want to be prepared to handle the variety of other file types for the machines with which they are paired. Additionally, having knowledge of how shapefiles work will give you a terrific leg up when it comes to file conversion and file sharing across multiple software platforms.
While rescue treatments won’t be a slam-dunk for every dirty data situation, there are a few possibilities.

Flow delays, as show in this harvest data set, may be fixable with a tool like Yield Editor.
Rescue Situation #1: Harvest Data
There are many situations that may require the cleaning up of yield data. Many of these reasons, however, will require an understanding of how a combine’s sensors send information to the display to calculate and document yield. Understanding how the movement of grain within the combine can create a delay in documentation may provide valuable insight when interpreting low yielding areas. These low yielding areas may actually be data errors which can easily be cleaned up, and not need further agronomic assistance.
In a situation where a few passes of harvest data seem out of place, a tool like Yield Editor could be a lifesaver, and can help clean up some of those gaps.
A free tool available through USDA ARS, Yield Editor gives the ability to visualize passes and make edits to the dataset. The system accepts two file formats – Ag Leader Advanced Text and John Deere GreenStar Text. If working with data in a format other than these, it must first be converted.
This software works to delete overlaps and re-adjust shifts in flow delays. Flow delays are the gap in time between the logging of the GPS point by the combine’s receiver and the logging of the weight by the mass flow sensor.
Remember that, in the end, every time data is removed or re-adjusted within a dataset, there’s risk of losing additional attributes, such as machine data. Also, modified or manipulated data removes some of the realities that might actually exist in the field. In some cases, that extra pass may have been very necessary to recover additional grain which is not taken into account, or perhaps that “zero” value was actually an area that we planted but had no crop.
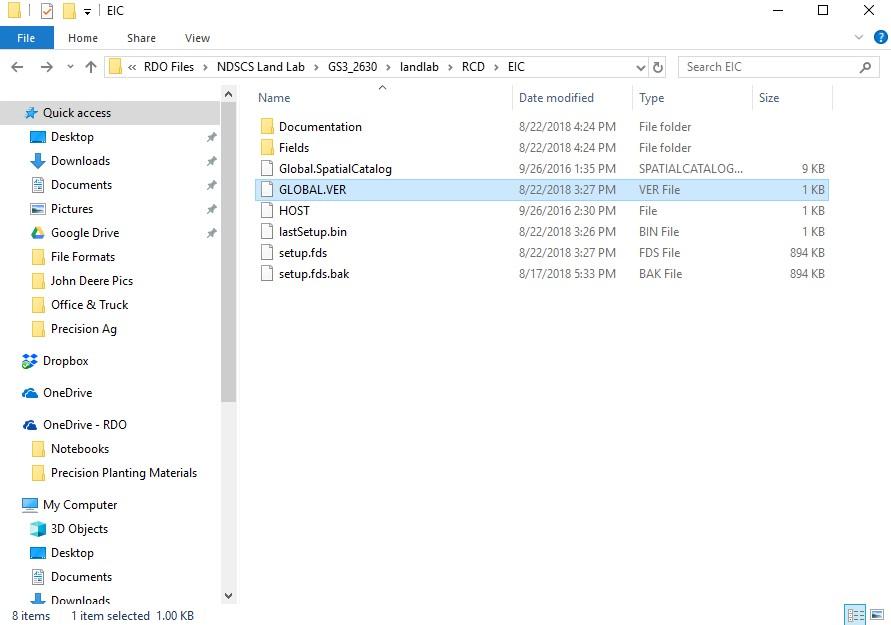
An example of a GS3 2630 file and what to look for if file corruption is the issue.
Rescue Situation #2: Corrupt Data Files
If the issue with a data file is that it seems corrupt or is unable to be uploaded and extracted, there are few things to look at.
First, make sure the software being used supports the file type. Some software does not support newer (or older) generations of given product lines, though there are some programs which can help with file conversion.
Second, make sure that the file structure is appropriate. If the software is having trouble reading the file, a couple things may be going on.
The lowest hanging fruit “issue” – and fix – may be the file being imported simply needs to be zipped.
Another area to evaluate is the file structure. A GreenStar 3 (or 2630) file, for example, is simply a collection of folders (profile/RCD/EIC) with a file found within the (in this case) EIC folder named global.ver that serves as the “index” file. Think of this file as the “Table of Contents”. In some cases, the index file is missing for whatever reason and all it takes to correct it is to create and save a replacement file in the right place in the file structure. This scenario is very generalized, but true of many machine file formats.
Rescue Situation #3: Post-Calibration of Data
The best way to ensure the accuracy and quality of a dataset is to make sure all machines and sensors have been calibrated prior to the pass. Of course, that doesn’t always happen, or isn’t always feasible. In those cases, virtually all software has the built-in ability to “post-calibrate” a dataset.
What that means is that the documentation will log “x” by adding up all bushels of grain or pounds of seed. However, if the number is known and doesn’t match that, it’s simple to “clean” the dataset by giving the computer the known final result and telling the software to re-calculate all data points so that the values match.
Finally, each software “post-calibrates” differently. For example, a few actually eliminate “zero” values in all datasets as they are imported. This is important to know prior to attempting to export and “clean” the data because some of the shifts that could be made in Yield Editor have potential to over-accentuate inaccuracies rather than improve them. Knowing the process going on behind the scenes by the algorithms in the software will go a long way in helping make the best decision on how to generate quality datasets for future decision-making.
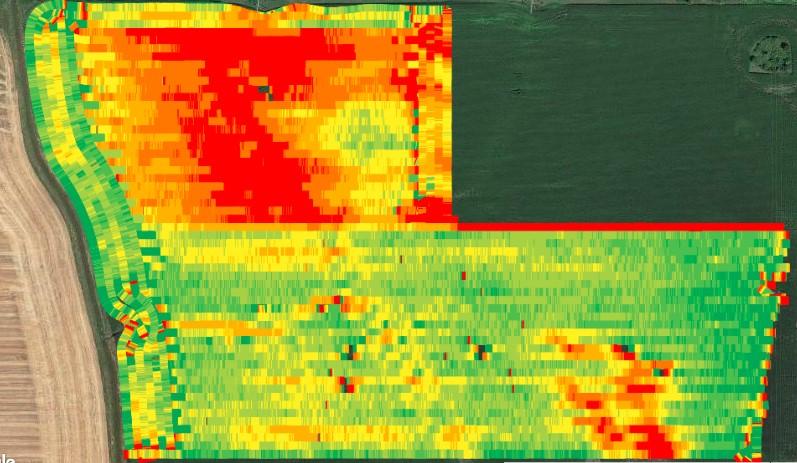
Some data issues, such as the overlap shown here, simply cannot be corrected. However, they can be teachable moments for growers to address in the future.
Looking Ahead
There are also some situations where data can’t be rescued. Yield Editor and post-calibration can only do so much.
In those cases, it might be best to cut losses and move on. While this may not be what a grower wants to hear, the upside is this can be a teachable moment. Take the opportunity to discuss areas that were unusable and explain how to improve in the future.
Subscribe Today For
